The AI world is full of acronyms, and MCP might just be my new favorite. Released by Anthropic in November 2024, Model Context Protocol (MCP) provides a shared, open standard for LLMs to communicate with arbitrary functions exposed as “tools.” While tool calling and agentic applications are nothing new, MCP launched with simplistic portability and pre-built integrations from major consumer products like Slack and Google Calendar, driving a wave of quick adoption. Now, there are thousands of open source, cross-compatible MCP servers powering a wide range of use-cases. With a familiar, client-server architecture (the client housing an LLM and the server exposing tools), MCP has already become a core staple of how many developers work on agentic applications.
Nevertheless, despite the numerous servers and projects already created with MCP, there is a key piece missing from the puzzle. From my perspective, developers have become hyperfixated. In the grand scheme of things, we are only tapping into half of what MCP can do. Zooming out can help lower costs, increase accuracy, and elevate the user experience—all with minimal effort.
Note: Want this blog in video format? Check out this 10 minute demo on YouTubeWelcome to Red Hat
My MCP story has its origins in May 2025, along with my summer internship at Red Hat. As an AI Engineering Intern, I was quickly introduced to Docling: a popular, open-source data preprocessor from IBM Research in Zurich (led by Peter Staar and Michele Dolfi). Simply put, companies want LLMs customized for their own use cases with their own data. However, this data often lives in PDFs, Word Documents, and Powerpoints—unstructured formats that are essentially unusable. Preprocessors like Docling bridge the gap, executing the (deceivingly complex) conversion to structured, machine-readable formats.
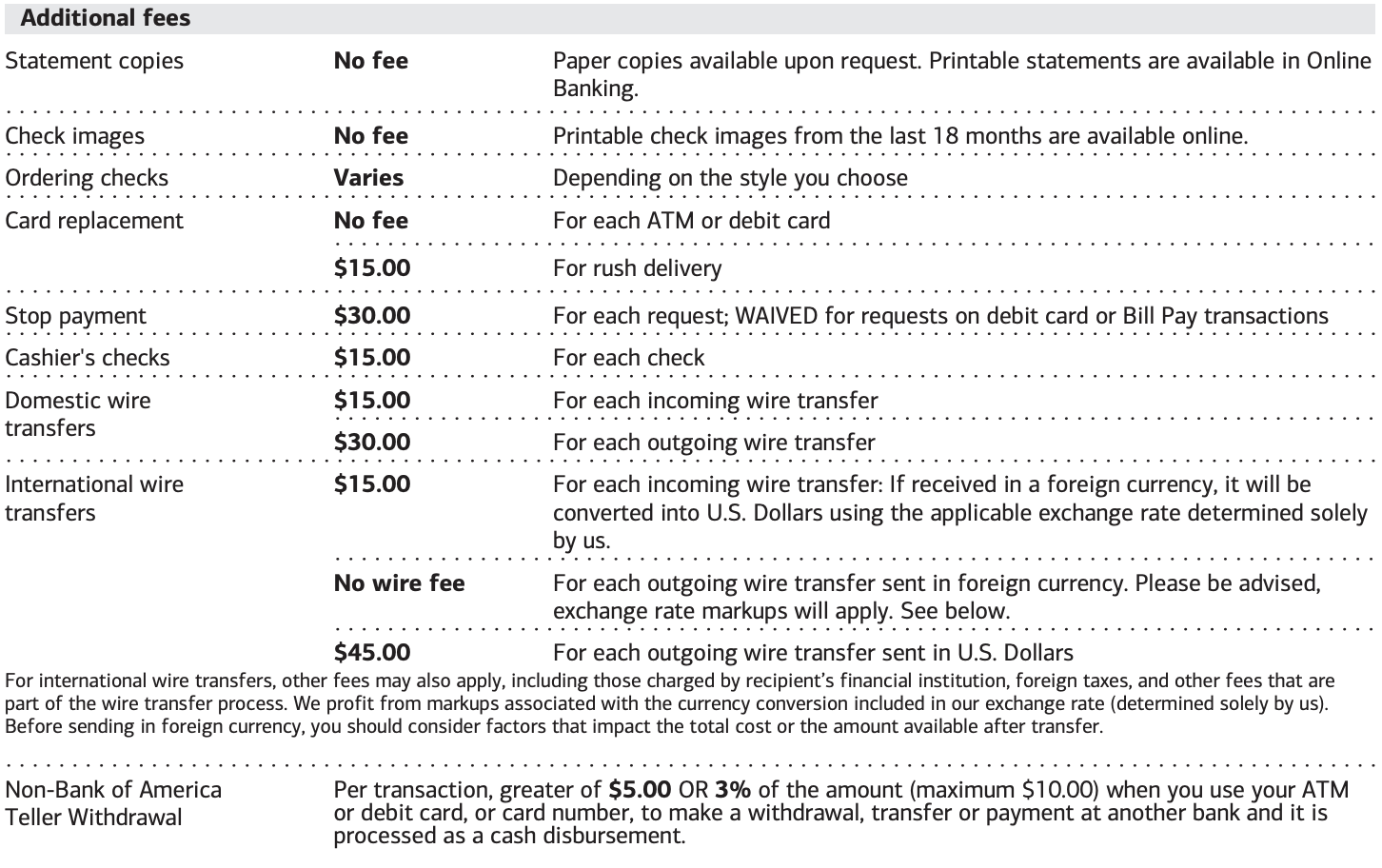
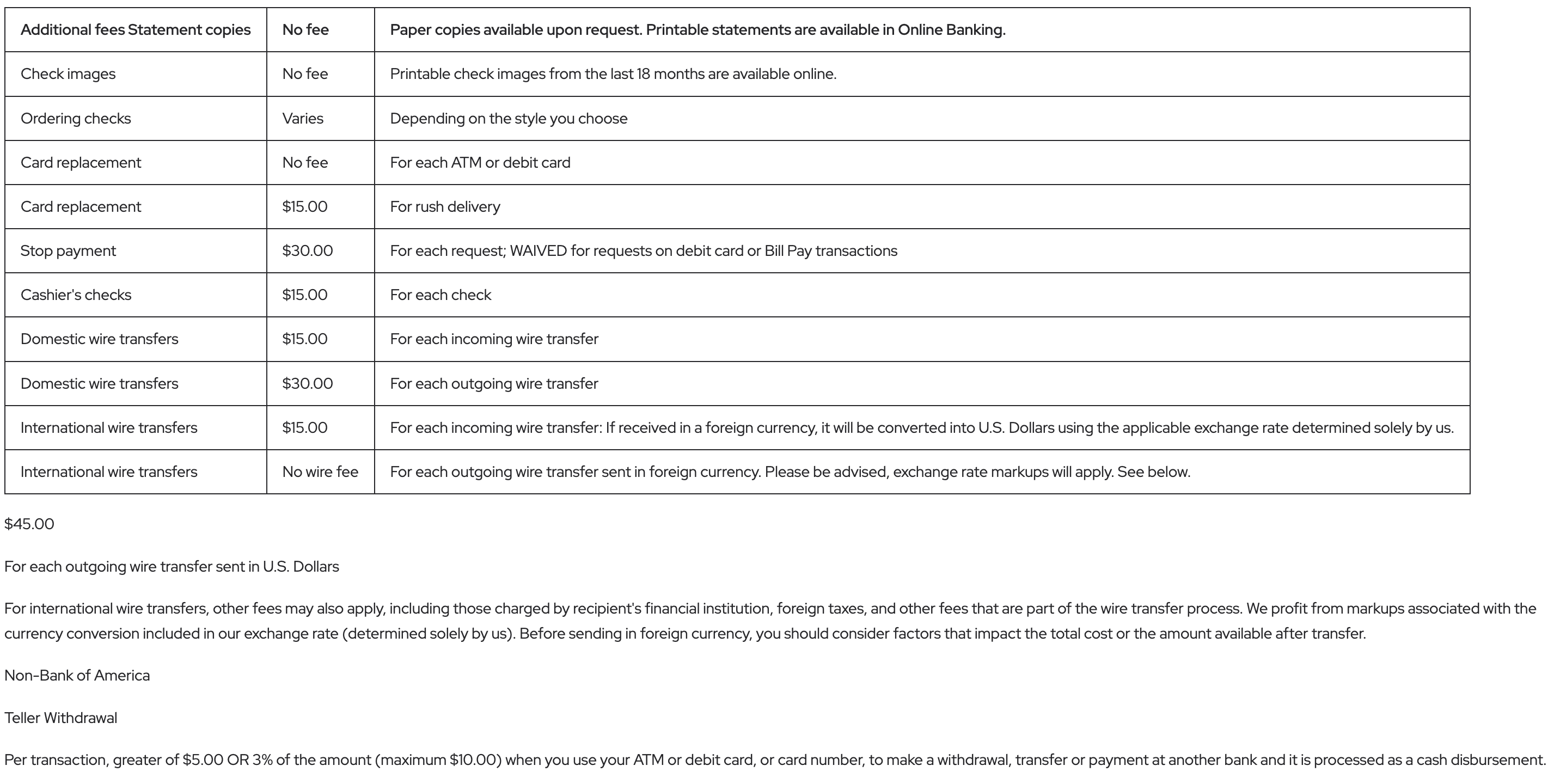 Table from the original PDF (top) compared with the Markdown representation of the converted table (bottom), using default settings in Docling
Table from the original PDF (top) compared with the Markdown representation of the converted table (bottom), using default settings in Docling
Among preprocessors, Docling excels in accuracy and extensibility. Regardless, complex documents can still cause issues. Take, for example, the large table above: part of a public account advertisement from a major bank. With merged cells, inconsistent font weights, and nonuniform borders, this table is challenging even for Docling’s cutting-edge internal models, leading to an improper output. The raw content is correct, but the formatting is not, with the last few rows “cut off” from the table and included as separate paragraphs.
At first, formatting discrepancies may only seem like a minor concern. But in reality, formatting is an important factor in “chunking” algorithms, which break documents into atomic sections of content small enough for RAG and fine tuning. Incorrect formatting strands related content across different chunks, leading to context issues down the line.
Recognizing the importance of formatting, our team conducted proof of concept (PoC) experiments to manually refine Docling’s conversion output. Bluntly, the results were not promising. To roughly edit Docling’s Markdown output for a two-page document, it took me over an hour of tracking down content and puzzling out syntax. For those unfamiliar with Markdown, the process was significantly longer.
 JSON representation of a Docling Document. The JSON representation is 6,000 lines long for a PDF file that was originally two pages
JSON representation of a Docling Document. The JSON representation is 6,000 lines long for a PDF file that was originally two pages
Even worse, editing Markdown files is a lossy solution. During conversion, Docling first populates a detailed “Docling Document” object in Python. This structure includes rich metadata (bounding boxes, parent-sibling relationships, etc.) that are omitted in the later transformation to Markdown. Ideally, conversion refinement would be done directly on Docling Documents to preserve this metadata, but the JSON representation for a couple of pages (as shown above) can be thousands of lines long. Clearly, automation was necessary; it became my job to make it functional.
To start, I spent a week with docling-core, digesting the full 4,000+ lines that define a document and contributing dozens of new methods. With functions to insert, delete, and update elements, it was now fully possible to programmatically edit a Docling Document; I crafted this repo for my team demonstrating fixes from our original PoC’s. Still, this was far from a final solution. Identifying desired changes was easy, but translating them to Python was hard. Something was needed to turn natural language descriptions into function calls. Sound familiar?
Enter MCP. Leveraging the semantic understanding of LLMs, I envisioned a solution in which users directed an MCP-based agent to make edits on their behalf. Luckily for me, this was not the first time that “Docling” and “MCP” had been uttered in the same breath.
Docling MCP
 README of the docling-mcp repository on GitHub
README of the docling-mcp repository on GitHub
Back in March, the Docling team had a similar vision to my own: expose the preprocessor’s powerful structure with an MCP server. Together, they created docling-mcp, a place for “making docling agentic.” The initial project—a FastMCP server with tools to convert and sequentially generate documents—was already exciting. However, these sequential operations (pushing to a stack) were not suitable for manipulation; for this, document elements needed to be nonconsecutively inserted, updated, and deleted.
Luckily, my work in docling-core provided a solid foundation. Over the next week, I mapped my methods to new and refactored tools for the MCP server. Alongside some auxiliary tools and a pull request from Peter Staar, the editing capabilities of docling-mcp quickly materialized.
At this point, prompt-based document refinement was possible, yet tedious. It was easy to communicate what needed to change in an edit, but where was far more difficult to align on. The primary culprit was a misalignment of vocabularies.
On one hand, humans are content-driven in our perception of a document: “the paragraph that talks about X.” Algorithms, on the other hand, require tag-based identifiers for elements. In Docling, these tags are implemented as “RefItems” (#/tables/1, #/texts/43), which point to remote “NodeItems” that store content. For humans, this representation is unintuitive, so I created an auxiliary content search tool to reconcile the two. This enabled RefItem-free prompts like, “Remove the copyright symbols in the section about Red Hat Enterprise Linux,” with the agentic process executing a search for referenced sections. With a text-based client like Claude Desktop, this was a near-optimal solution.
 Sample editing interaction with Claude Desktop utilizing the keyword search tool
Sample editing interaction with Claude Desktop utilizing the keyword search tool
Nevertheless, I had my doubts. To me, the circumlocution of document elements felt clunky and unnecessary; it would be far simpler to talk about “this paragraph” and “that table.” Furthermore, the agentic loops and tool calls for element searches contributed unnecessary costs and potential breakpoints.
To remedy this, I saw it necessary not just to build an MCP server; we needed a custom, Docling MCP client. While popular clients like Claude Desktop are brilliantly optimized and extensible, they suffer from the bounds of generality: limited to interfaces and architectures that serve all use cases. In contrast, specialized, agentic applications with confined scopes—a combination of MCP servers and clients—unlock free and valuable context. Recognizing this, I qualified my pull request that implemented the keyword search with the following note:
“I am exploring on the side the idea of creating a standalone Docling client that uses a GUI to allow users to select parts of the document to go along with their prompt as RefItems, eliminating the entire need for anchor helper tools on the server side”
With this, the stage was set, and with only a couple weeks left in my internship, the clock was ticking. It was time to go from MCP server to full-blown agentic application.
The Agentic Application
Already familiar with Anthropic’s models and API, I used this quickstart tutorial to spin up a basic, CLI-based MCP client running in Python. Immediately, I had full control over the system prompt, context packaging, and tool result formatting, as well as the ability to lower my spend with prompt caching and context compression. Of course, these capabilities are not unique to custom clients, but they can be more effectively leveraged for these specific use cases with narrow requirements.
After this, I shifted my attention to the user interface. With FastAPI, I turned my CLI client into a simple API backend—capable of receiving user prompts, storing context, and streaming responses to the frontend. Then, from a local fork of docling-mcp, I passed Docling Documents as JSON between the frontend and backend, enabling edits to be viewed in real time.
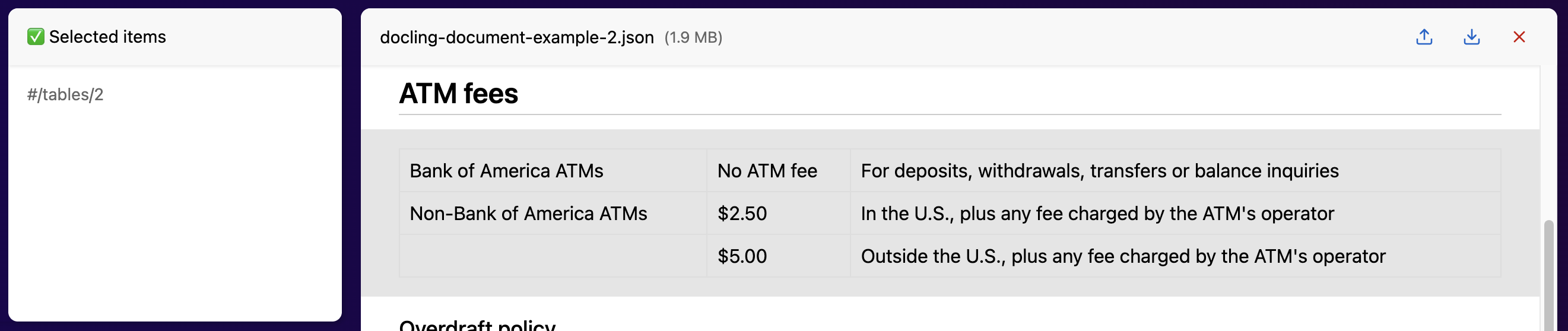 Display showing the embedded connection between RefItems (left) and elements in the user interface (right)
Display showing the embedded connection between RefItems (left) and elements in the user interface (right)
Next came the “key piece” to the puzzle. Using the typescript definitions in docling-ts, I quickly vibe-coded a Docling Document viewer. The design presented elements in a simple, clearly delimited manner: displaying documents “as they would be ingested.” Most importantly, every element in the design was linked to its RefItem, as seen from the tags in the “Selected Items” tab above. Thus, each click communicated a critical piece of context, which I then processed and appended as a tag/content pair to each user prompt. No longer were tool calls necessary to locate RefItems—a massive improvement in terms of cost, speed, and reliability.
Following this major addition, the rest of the prototype came together quite quickly. Within two days, I added a chat window, upload/download controls, efficient edit history, context clearing, execution interruption, and a cost observance panel. Combined, these gave users greater control over a non-deterministic system.
Furthermore, with the text-based nature of LLMs, making improvements to the performance of my project was a straightforward process. When it came time to implement table editing, most of the work was done by adding an HTML representation in the user prompt and a few directions in the system prompt. Of course, the actual process was a bit more complicated, but this captures the core, underlying message: Agentic applications are supercharged by context. Specialized applications with custom clients can provide tailored, high quality context with minimal cost.
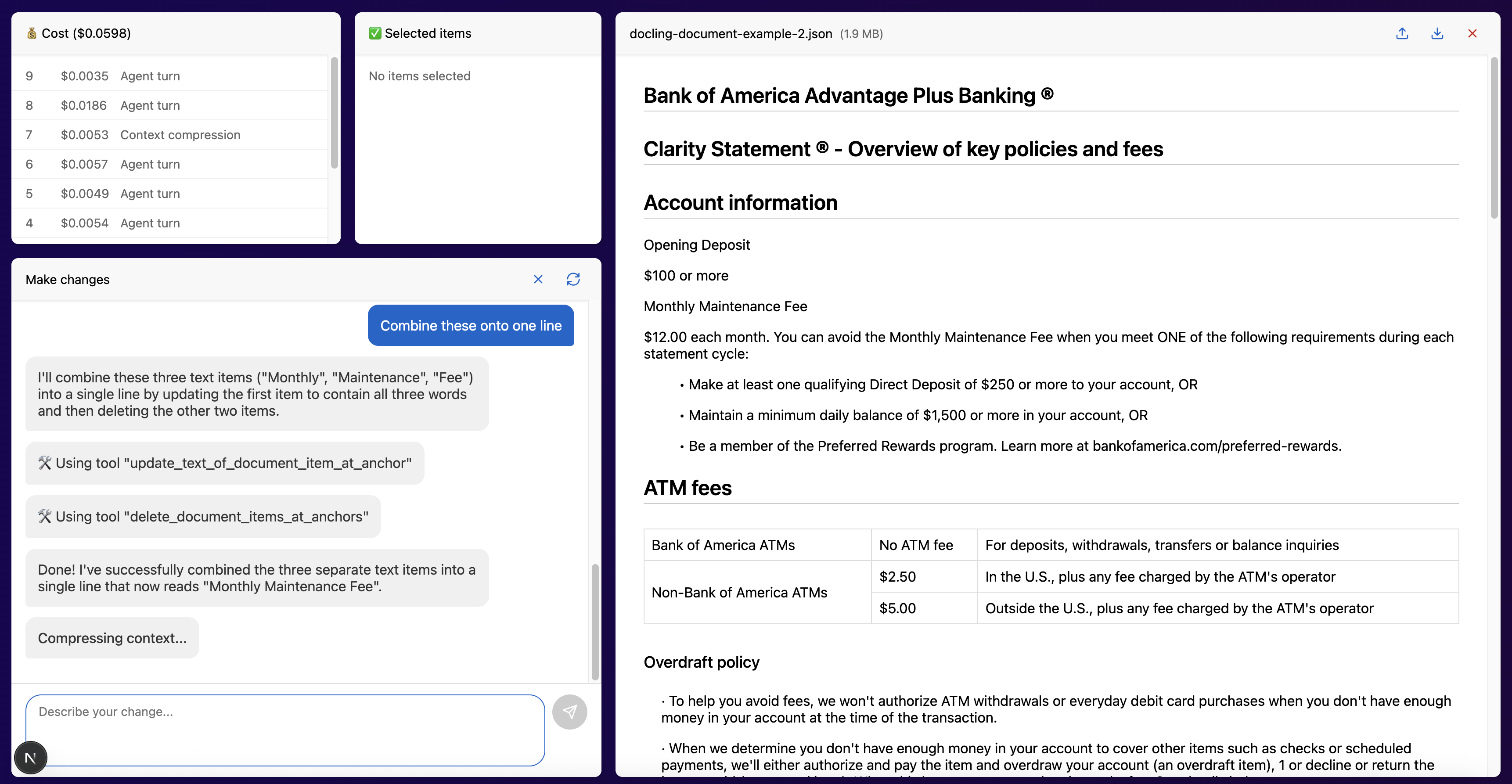 View of the final document editor prototype. The agentic assistant (bottom left) is currently undergoing context compression to enable a continuous conversation. Check out the videos to see this tool in action!
View of the final document editor prototype. The agentic assistant (bottom left) is currently undergoing context compression to enable a continuous conversation. Check out the videos to see this tool in action!
Once completed, I put my prototype to the test with the same documents from our team’s original PoC’s. The results this time were extremely promising. In just over 10 minutes, I was able to fully clean the document that once took me over an hour: an efficiency gain of at least 80%.
Moreover, my AI-assisted revisions were much higher quality than the manual ones. Beyond fixing obvious errors, I made each document “RAG ready” by turning complex lists into tables, adding supplementary content, and generating XML-tagged table descriptions. Overall, I was freed from execution to focus more on ideation, leading to a far better result.
A Bigger Picture
So what does this all mean? Right now, it seems as though every tech-adjacent company in the world is racing to have its own MCP integration. Built as MCP servers, these integrations “reach users where they are” on Claude and other similar AI engines. Conversely, aside from code editors and productivity assistants, there seems to be much less action and experimentation in the direction of MCP clients.
To a certain extent, this makes a lot of sense. It is far easier to stand up an MCP server (especially from an existing API) than it is to create an MCP client. Additionally, it is difficult to imagine competing against monoliths like ChatGPT and Claude.
Regardless, as embodied by my own experiences, there are inherent advantages that lend themselves to specialized agentic applications. Simply put, there are too many industries and too many use cases for a single client to effectively encompass them all. With AI applications rather than integrations, there exist opportunities to eliminate circumlocution, impose helpful constraints and infuse prompts with swaths of free context. Just as we are elevating performance within agentic loops, we must also innovate in the prenascent stages before a prompt is processed: guiding better inputs that lead better outputs.
So there you have it: my Red Hat journey to build an agentic application for Docling, rather than an MCP server integration. Given the ever-evolving nature of AI, I expect most (if not all) of my opinions on the matter to morph and mature through further discussion. Thus, if you have any questions, comments, or quarrels about my work, please reach out to [email protected], and I will be happy to chat.
The world is changing before our eyes, and it’s up to us to shape it. What an excitingly terrifying time to be alive.
Note: The code for the Docling Document Editor prototype can be found in this repository. The repository is messy and experimental with no clear directions to run locally. However, plans are underway to include this project as a new sub-repo of Docling, in which case further documentation will be added.