This post summarizes our recent effort to make social media links display a preview card. In the process, we gained a lot of insight about CourseTable's infrastructure setup. We will also share the paths we've explored and our eventual solution, hoping that these conclusions can help others in a similar situation.
(Aside: you can't imagine how much CourseTable testing relies on AFAM classes, just because they are always at the top of the catalog)
This post will be technical, but we will try to keep the explanations accessible to anyone familiar with the web. It is mainly intended for developers wanting to set up similar technologies for their website.
Motivation
People often want to share courses with each other. While it's often fine to just say "check out LING 253, it's a cool class!" (it is, by the way), it is not as convenient as just sharing a link that others can directly click on without typing in extra search terms.
CourseTable is a client-rendered site (more on this later). Any view change, such as switching pages, opening up the course modal, etc., is driven by React running in the user's browser. In this kind of website, it is not necessary to encode the state in the URL, because we are not communicating with a server to fetch new page content. This means there used to be no difference between URLs of two pages displaying different courses (they were both just https://coursetable.com/catalog).
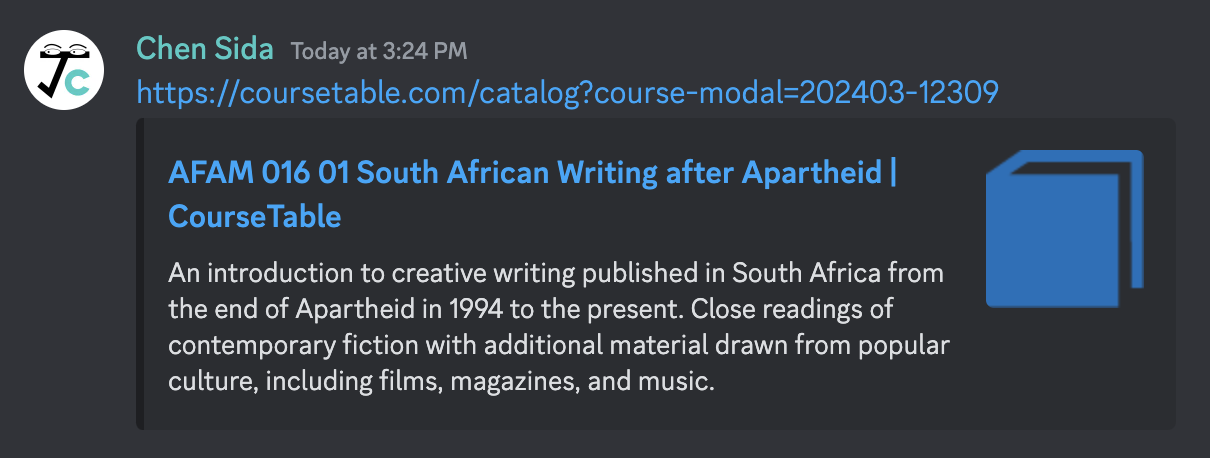
Last semester, we gave each course a unique URL, which looks like https://coursetable.com/catalog?course-modal=202403-10471. Opening that URL directly opens up the corresponding course information modal. This is great! However, in social media and messengers, the preview card that gets displayed alongside the link still shows information about CourseTable, not about the course (we took this screenshot after the feature is already live, but imagine the URL contains a query):

This means others still cannot understand what you are talking about, until either you explain further, or they click on the link!
To understand why it behaves like this, and figure out how to potentially improve this behavior, we need some knowledge about the technical details.
Background
Social media apps generate link previews using automated tools called crawlers. When your message contains a link, the app sends a request to that URL and parses the HTML response. The HTML contains metadata that looks like:
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>AFAM 016 01 South African Writing after Apartheid | CourseTable</title>
<meta name="description" content="An introduction to creative writing published in South Africa from the end of Apartheid in 1994 to the present. Close readings of contemporary fiction with additional material drawn from popular culture, including films, magazines, and music.">
<meta name="og:title" content="AFAM 016 01 South African Writing after Apartheid | CourseTable">
<meta name="og:description" content="An introduction to creative writing published in South Africa from the end of Apartheid in 1994 to the present. Close readings of contemporary fiction with additional material drawn from popular culture, including films, magazines, and music.">
<meta name="og:locale" content="en">
<meta name="og:image" content="https://coursetable.com/favicon.png">
<meta name="og:type" content="website">
<meta name="twitter:card" content="summary">
<meta name="twitter:image" content="https://coursetable.com/favicon.png">
</head>
Different crawlers might decide to use different meta tags. In our case, we focus on the tags that begin with og, part of the Open Graph protocol, which is designed to give social media platforms the information they need to generate a preview. These metadata are all that's needed—the actual displayed content of the page doesn't matter. Once the crawler finds the title, description, thumbnail image, etc., it can use those to generate a nice preview card.
In React, there's a library that injects tags into the HTML head, called react-helmet. Naturally, we first tried injecting these meta tags when a course modal gets opened: #1427 (redone in #1645 featuring Alex wrestling with Bun per usual). This was a small step in the right direction – now when you open a course modal on CourseTable, the browser tab title does change to the course title. However, the social media cards still showed the default metadata :(
So now we were faced with the question – where does the HTML that users see come from, and why can't crawlers see the same content?
CourseTable's frontend and backend are isolated from one another. Our frontend is hosted on Vercel while our backend is a self-managed server hosted on DigitalOcean. Our DNS (managed by Cloudflare) points coursetable.com to Vercel's server, so when the user opens the page https://coursetable.com/catalog?course-modal=202403-10471, the browser first makes a GET request to Vercel. Vercel has its own logic to map the URL path (/catalog?course-modal=202403-10471) to an HTML file that's returned as response, but, as far as we know:
- The query string (
?course-modal=202403-10471) will not cause Vercel to serve different HTML. - More importantly, CourseTable only has one single HTML file: index.html!
CourseTable is a typical client-side-rendered (CSR) application: the server only serves one HTML file, which contains no visible content, but links to a bunch of JavaScript and CSS to be loaded. The loaded JS then reads the browser address and populates the blank page with content.
You can check the index.html in our GitHub repo. As you can see, it does contain the site-wide title and description metadata. Once the page loads in the browser, React then kicks in and fills in everything, such as reading the query string and replacing the default metadata with course-specific ones. However, this happens after JavaScript loads; and, as far as we know, crawlers don't run JavaScript. They only read the initial HTML response.
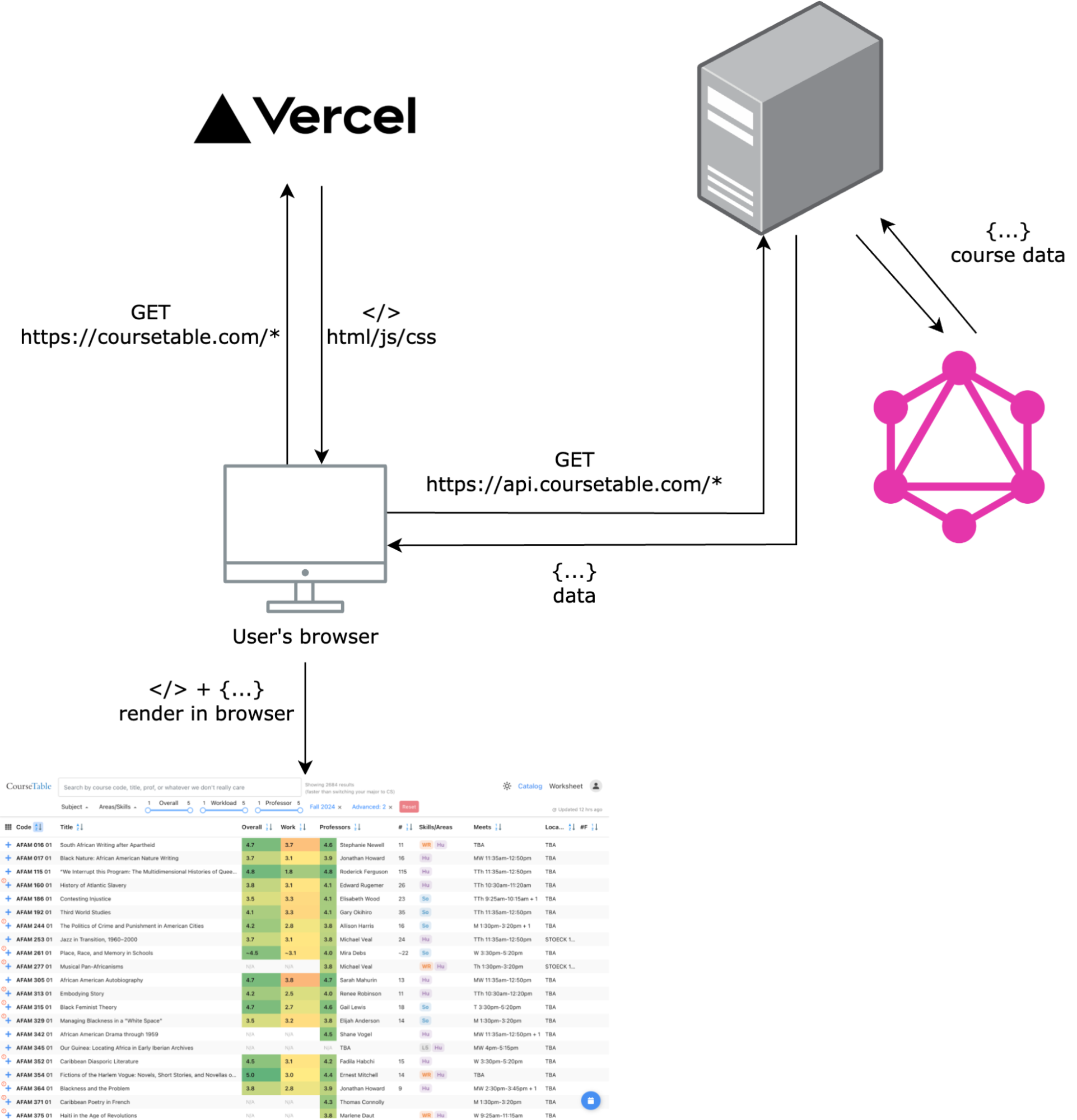
Once the JavaScript loads, the user's browser starts making further requests to API endpoints at api.coursetable.com. This is our backend server that handles things like adding friends, storing worksheets, sending course data, etc. Unlike Vercel, it can react to whatever request in whichever way we want.
So now we are at an impasse.
- Crawlers want nicely rendered HTML containing all the data they need without running any JavaScript.
- Vercel only serves HTML that we uploaded; it can't generate HTML on the fly when a request comes in (that is called server-side rendering, or SSR—which our service doesn't provide).
- We only ever upload one HTML file, because that's how CSR works. And even if we do generate one HTML for every single course, the problem remains that course-modal is a query string, and Vercel can't serve different HTML based on the query.
- If Vercel doesn't want to dynamically generate HTML, we can modify the HTML after-the-fact using React in the user's browser, but crawlers don't run JavaScript.
- We do have an API server that's fit for this kind of task, but bot traffic goes to
coursetable.com, not toapi.coursetable.com!
So it seems no party is willing to collaborate and play nice. What gives?
Aside: You might ask, why don't we just change the URL to https://coursetable.com/catalog/202403-10471, so Vercel can serve the catalog/202403-12309.html file? Well there are still two problems: (1) there are hundreds of thousands of courses growing by several thousand every year; (2) course modals can be shown on other pages too, such as by clicking a course in your worksheet, which means… we have to have another set of HTML files that get served for https://coursetable.com/worksheet/202403-10471. That's a lot of HTML. We can't build so much HTML in reasonable time, and Vercel definitely has an upper bound to how much static assets we can store in it. This option was never considered or experimented with, but we did built infrastructure to statically pregenerate HTML for every URL at #1536 (which Sida requested Alex's review on last year and he still hasn't…), in case it's useful for some future use case.
Prelude: public data access
Concurrently, the team was also interested in making a public version of CourseTable that did not require a Yale login! However, due to our currently-awesome-but-historically-contentious relationship with the Yale administration, we had to be very careful to not show any proprietary Yale data (i.e. reviews and ratings). This was another long and arduous process that may deserve its own blogpost at some point, but after hundreds of commits, reconfiguring our Hasura GraphQL engine, and importantly getting the color of the blur to match our theme (thanks Tyler)  we had it working.
we had it working.
It's live right now, go tell your parents/non-Yale-friends-or-loved-ones to go to https://coursetable.com/catalog to help you choose your classes!
The public data access was independently motivated, but aligned quite nicely with this work: in order to generate link previews, we have to expose some data to the internet anyway, so it's time to open up and not guard all data behind authentication (but we still guard the important stuff, don't worry Yale).
Failure, failure, failure, and then success
We already mentioned several attempts that were quickly ruled out: using react-helmet to dynamically swap out the head metadata, statically pregenerating HTML for every URL, Sida sitting at his computer 24/7 writing custom metadata for all incoming requests. There's something valuable to take away from each attempt, but we need something more sophisticated than these common-class solutions.
Letting backend return HTML
We said we have a backend server that handles requests and returns whatever response we desire. Naturally we want to see if it can respond to these crawler bot requests and generate HTML on-the-fly. We made #1630 and it almost worked (in fact our eventual solution is very similar to this) except for one critical problem: we can't make the bots go to this URL. The API sits at api.coursetable.com, but bots go to coursetable.com—the same domain that human users go to. Vercel is not smart enough to do us the favor and direct bot traffic to another domain, so it would serve the same HTML as humans see. If we add a redirect in our DNS, then human users would get redirected to the backend too—at which point Vercel is useless if the server is serving everyone (and we like Vercel because a CDN is always faster than a centralized server!)
We need a way to tell bot traffic apart from human users. This is not impossible—when bots send requests, they (are supposed to) carry a User-Agent HTTP header that identifies them as bots. For example, here's the header sent by a Mac laptop to our server:
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36
And here's the header sent by Slack bot, as claimed in their docs:
User-Agent: Slackbot-LinkExpanding 1.0 (+https://api.slack.com/robots)
So in our long relay of request handling, is there a party that, based on the HTTP headers received, can do the redirect? We first looked at the potentially obvious answer: the target of the URL, Vercel.
Vercel edge functions
We said "Vercel is not smart enough to do the redirect". That's true by default because we only employ a simple CDN. But Vercel offers another service that allows us to hook into each request and do custom things: Vercel edge functions.
(Note the date, took months before serious work began)
A Vercel edge function takes a request as input, runs some custom JavaScript, and emits a response or passes it forward to the CDN service. It does come at a cost: Vercel charges us based on the number of runs, the total execution time, resources used, etc. But we don't actually need that many edge function runs… right? We estimate that 95%—if not more—of our traffic come from human users and those can go through the old path of having no middleware. We just need the edge function to be revived and working when the User-Agent header contains a particular substring, so bot traffic can receive a different HTML.
We didn't find much useful information in Vercel docs, partly because it's so coupled to Next.js, their own React-based web framework, which we are not using, so it's hard to tell which APIs are available in bare Vercel and which are only available via Next.js. We contacted Vercel support, and after some back-and-forth, (thanks Sebastian)  we reached the conclusion that it's not possible to only invoke the expensive edge function for certain user-agents—the way edge functions work is they would always get triggered and then check the user-agent, realize it's not interesting and do nothing, but would still count against our quota. (If you are reading this and you believe we reached the wrong conclusion, please contact us and let us know.)
we reached the conclusion that it's not possible to only invoke the expensive edge function for certain user-agents—the way edge functions work is they would always get triggered and then check the user-agent, realize it's not interesting and do nothing, but would still count against our quota. (If you are reading this and you believe we reached the wrong conclusion, please contact us and let us know.)

We don't really know how much Vercel traffic we are getting, but it would be a lot, since every time you open a course modal or go to a different one, the server would get a separate request. We don't want to risk our bill and experiment, because Yale Computer Society is not a money-printing machine.

(1M as in 1M of free request quota, not 1M$)
Cloudflare rewrite rules
While Alex and Sida are scratching their heads thinking it's not possible without handing money to Vercel despite them actually not doing much useful, our all-time-hero, Neil, casually pointed out another service we missed: Cloudflare!
We always painted Cloudflare as "just a DNS" that takes a URL and returns a server address. But as many of you may be aware, it is capable of doing much more, and we discovered one of the things it could do: conditional redirects based on user-agents, also completely free in our plan! This is exactly what we were looking for. We all got super hyped.
The plan was simple: for requests to https://coursetable.com/catalog?course-modal=202403-10471, Cloudflare first checks the User-Agent header. If it contains one of the substrings known to belong to a crawler bot, we redirect the request to https://api.coursetable.com/api/link-preview?course-modal=202403-10471 instead, where we have our own API server to do its magic and return the HTML containing the right metadata. Otherwise, if it is not a crawler bot user-agent, the redirect will not be called.
It's not a single configuration addition, though. There were a few hiccups.
Cloudflare offers two similar services, one called "Transform Rules" and one called "Redirect Rules". Confusingly, "Redirect Rules" was not the one we want: crawlers refuse to follow redirects. If the server returns a 301 or 302 response, the crawler would just bail.
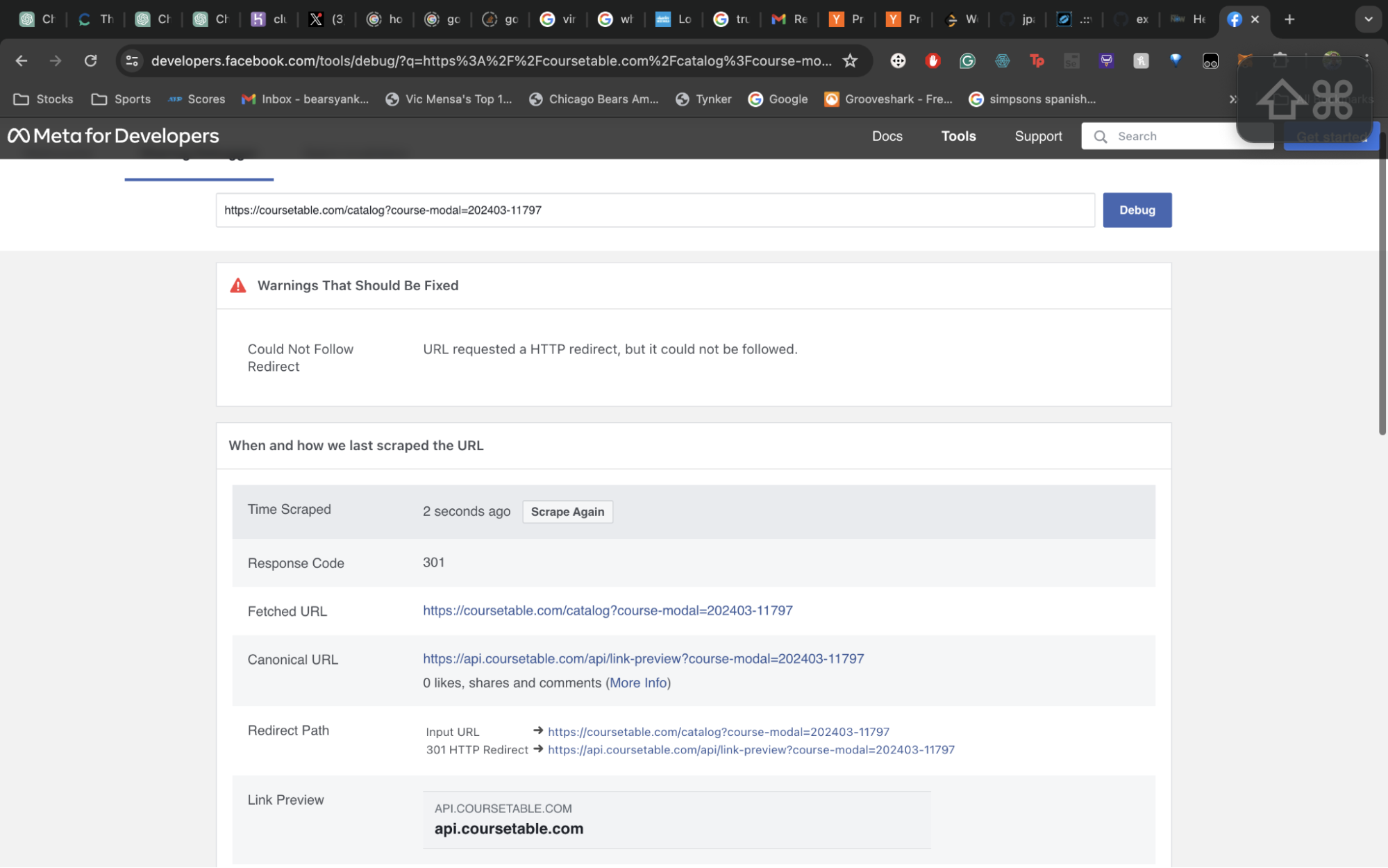
Therefore, instead of asking the crawler to follow the redirection to another URL, we needed to do the redirection under the hood and pretend to the crawler that the resource (with the correct metadata) is the exact link it is crawling. "Transform Rule" turned out to be what we need, per Cloudflare's description:
Return the content of a rewritten URL from the origin server. The visitor's browser will still display the original URL.
However, we then discovered that Cloudflare transform can only be used across the same origin URL–requests going to coursetable.com can't be rewritten to go to another origin such as api.coursetable.com which is what was needed. We solved this issue in 2 steps:
- A transform rule rewrites the request path from
/catalog?course-modal=202403-10471to/link-preview?course-modal=202403-10471, given the condition that the path starts with/catalogor/worksheet, and it contains acourse-modal=query, and the user agent contains one of the recognized bot names. - A page rule listens on
coursetable.com/link-previewand forwards the URL toapi.coursetable.com/api/link-preview. This redirect happens behind the scenes—the bot still sees the previous URL before the transform.
We thought we had solved it. But still, the link preview showed up with the default title/description for CourseTable (from our homepage)—even for the API endpoint URL itself?! We were baffled because it means the API was correctly wired, but the query with the course information got removed. We spent a while looking for logs, but it was nowhere to be found.

It was hard to test this in a browser too, because browsers set the user agent by default. Nevertheless, it's at least possible to set the user agent string manually in Chrome. So we added facebook to our user agent and ran manual tests. Finally, through lots of manual inspection, we figured out that page rules actually drop queries by default: we have to use a wildcard to preserve everything that comes afterwards, like this: coursetable.com/link-preview* -> https://api.coursetable.com/api/link-preview$1
Finally, 5 months since the idea was first brought up, everything seemed to work!
One final struggle was figuring out the right user agent strings to search for. We discovered that Cloudflare rule expressions match strings case-sensitively, and fancy matching requires business plans :( So we had to actually search for the user agent strings for every bot, because in one camp we have facebook, pinterest, and discord, while in the other camp we have LinkedIn, Twitter, and WhatsApp. It was a quick struggle though, and we cobbled together something working on all platforms we cared about.
Above all, it's all FREE, so we have more budget to spend on funsies:

As promised, we are including all these funny Slack exchanges in this post, just to show you what we have been through:

Further improvements
We don't plan to stop here. We have several improvements in this vein in our todo list:
- Currently, the preview only contains plaintext, which is straightforward to retrieve. We want to dynamically create images to show up in the preview, similar to how the image preview for a tweet is the tweet itself. We still want to figure out exactly what that image should be—whether it's purely text-based, a collage of course-related images, or a combination of both—if you have any thoughts, let us know!
- We want to serve real HTML, rendered from our frontend code, instead of a fake HTML file that only contains head metadata. This may be important because we are soon allowing search engines to index each course (#1709), and the more information we have, the more discoverable the course pages are.
- We also plan to further enhance our general handling of metadata to include information such as last modified (#1619), professor(s), related courses, and other relevant data, which is useful for search engine display.
This experience has not only improved how CourseTable links appear on social media but also enables CourseTable courses to be indexed by search engines. For us, it provides valuable insights into our tech setup and experience for handling similar issues in the future. It is a great example of why we think CourseTable is so great. Through collaboration, creativity, and perseverance, we have made CourseTable more robust and user-friendly than ever before. We continue to fulfill our goal of making course selection and sharing as seamless and informative as possible for all Yale students—all while keeping it completely open and free.
If you enjoyed this blog post and/or are a regular user of CourseTable, consider supporting our work through buymeacoffee! And if you found this post to be thrilling and aligned with your interests, consider applying to join the team next fall! We are always looking for talented and passionate individuals who want to dedicate time to working on a project that virtually all their peers use.